CuccioloFinder
Italian shelter dogs, scraped and translated into one searchable site, with two independent AI breed signals per dog.
TL;DR
CuccioloFinder gathers adoptable dogs from five Italian shelter sites into one English-language search experience. The technical core is a worker pipeline that runs five Scrapy spiders, translates Italian shelter listings, extracts structured fields (size, age, compatibility, medical status) from free-text descriptions, and produces two independent AI breed signals per dog: a Vision Transformer top-k over the dog’s photos and a typed-similarity scorer against the AKC catalogue (the American Kennel Club’s reference list of recognised breeds and their attributes) weighted by information gain. A natural-language smart-search page lets a visitor describe their ideal dog in plain English; an LLM extracts the filters and the page renders them back transparently. Every LLM workload (translation, extraction, search) can be served by local Mistral 7B or by Llama 3.3 70B on Groq or OpenRouter, chosen per workload.
Approach
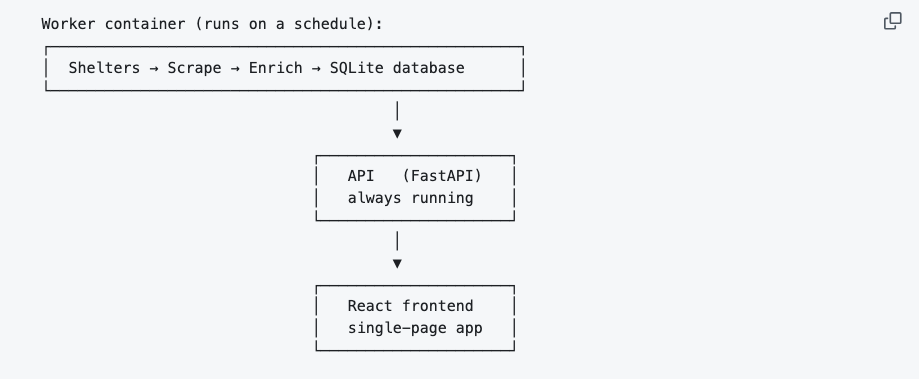
Two containers, one Docker image. The worker runs on a schedule: five concurrent Scrapy spiders, three enrichment stages (translation, per-field extraction, breed inference), then it exits. The API stays up: FastAPI + SQLAlchemy, in-memory caches for filter enums and dashboard aggregates, refreshed by the worker at the end of each run. Both write to and read from the same SQLite file on a host-mounted volume.
I picked this shape for three reasons.
- Different lifecycles, crash-isolated. Worker is a scheduled batch job that exits; API is a daemon. A scraper crash or a Mistral OOM in one container doesn’t take down the other, and per-role memory limits and restart policies follow naturally from the split.
- SQLite as a shared boundary, not a service. One file on a host volume, both containers mount the same path. No managed DB, no separate ops budget, no network hop. The API’s cached endpoints (
enums,stats) don’t touch SQLite on the hot path, so the worker’s writes during enrichment don’t block them. Smart search does degrade because it shares the API’s Mistral instance; the frontend surfaces a maintenance banner on that page during worker runs. - One Mistral in RAM. The worker calls
/api/translate/descriptionon the API rather than loading its own GGUF, so the 4.4 GB model lives in memory once across both containers.
Nginx fronts everything for SSL, routing, and per-IP rate limits; the React SPA builds to static files served from the same VPS.
Key decisions
- Breed similarity: chose a typed per-dimension scorer (ordinal for size / fur / weight, set-with-IDF for temperament, exact-match for the rest, weighted by information gain over the AKC catalogue) over sentence-embedding cosine, because cosine scores collapsed into a 0.95+ band for nearly every (dog, breed) pair and carried no real ranking signal. Scores now spread across
[0, 1]and the top-ranked breed actually means something. - LLM serving: chose to add hosted Groq and OpenRouter paths to the original local Mistral, and made each workload (translation, extraction, search) pick its backend independently via env var. The trigger was operational pain on the 8 GB CPU-only VPS: Mistral’s ~4.4 GB resident footprint, frequent OOM kills on long descriptions, slow CPU inference. Hosted Llama 3.3 70B gave 128k context (no chunking), remote hardware (no local RAM), and low latency. Decoupling per workload let bulk translation sit on Groq’s free quota while per-row extraction went to paid OpenRouter.
- Sentinel writes for “no signal”: chose to write
""/[]on a successful “no signal” LLM call over leaving the columnNULL, because every nightly run was otherwise re-asking the same LLM the same dead-end question on hundreds of descriptions.NULLnow means “never tried, or just invalidated”; the sentinel is the gate that prevents the redundant call. - Per-field extraction calls: chose one LLM call per extracted field per dog over a single combined call, because a single bad response on the combined path then poisons every other field on that dog. The per-field path costs more tokens but isolates failures and lets each field’s prompt be tuned independently.
Results
- Deployed and serving public traffic on a single 4 vCPU / 8 GB Hetzner VPS, CPU-only PyTorch, no GPU. The OOM mitigations and sentinel cache below are what keep the deployment on the smallest tier that fits.
- 5 shelters, 143 active dogs in the live dataset; rebuilt nightly by the worker.
- Description chunking at ~800 chars + input-scaled
max_tokens = max(50, len(text)//3)eliminated Mistral OOM kills on long descriptions and the duplicate-translation hallucinations that filled the output buffer on short ones. - Sentinel writes drop the steady-state per-run remote-LLM budget to (new dogs) + (descriptions that changed); fields where the description genuinely lacks the information are not re-asked.
- Breed scorer moved from a 0.95+ collapsed cosine band to scores spread across
[0, 1]; the top-ranked breed actually carries signal.
Stack
Python, Pydantic, pytest, asyncio, FastAPI, SQLAlchemy, SQLite, Scrapy (+ Playwright), Mistral 7B via llama-cpp-python, Llama 3.3 70B via Groq and OpenRouter, Vision Transformer (HF Transformers, CPU PyTorch), React 18, Vite, recharts, @nivo/heatmap, Docker, Docker Compose, Nginx, Hetzner, GitHub Actions.